|
|
很多优秀甚至伟大的产品决策,并非通过数据发现的,而是一个产品经理综合智慧的体现。

产品经理所面对的数据,本质上和日常生活中的数据没有太大的差别。简单来说,都是一个量化事物的手段,就像身高、体重一样,都是一个数字指标,它代表了现实存在的事物的一个客观情况。
正是因为数据的客观性,让数据变成了发掘问题本质,寻找事物规律所需要用到的最有利的手段之一。
数据虽然客观,但是有时也会骗人,而且骗人的方式不同。
1、障眼法欺骗
案例一: 把沉默用户当做支持和反对的中间态
2家网站A和B,都经营类似的业务,都有稳定的用户群。它们都进行了类似的网站界面改版。改版之后,网站A没有得到用户的赞扬,反而遭到很多用户的臭骂;而网站B既没有用户夸它,也没有用户骂它。如果从数据来看, 应该是网站B的改版相对更成功, 因为没有用户表达不满。但事实并非如此。网站A虽然遭到很多用户痛骂,但说明还有很多用户在乎它;对于网站B,用户对它已经不关心了.网站A指的是Facebook,网站B是微软旗下的Live Space。
案例二: 把某一类型数据当做全部数据导致分析结果错误
某产品想要看网站现在的用户访问量是什么状态,于是选择了PV作为观测指标,通过alexa来看网站的PV在过去一年中呈明显的下降态势,于是就以此为论据进行了分析。
可是后来发现,alexa仅仅统计通过WEB的访问量,而用户移动端的登录并不在统计范围之内。由于微信等移动端应用的使用,一大部分人会通过移动端的途径进入,缺失这部分数据意味着前面统计的数据基本没有意义,因为WEB端访问量的下降有可能是用户访问网站次数降低,同时也有可能是由PC端向移动端迁移,这个统计就不能作为论据出现了。
2、单一欺骗法
案例一:将指标分开单一看,忽略多环节指标
在统计用户反馈的时候,只看到几个用户反馈一个问题,这些反馈在整个问题里占比只有1%,你觉得这个太低了,不加以重视!但是,你不知道另外99%遇到这个问题的用户很可能卸载你了!!!
案例二 : 高流量即高转化?错!
一篇文章百度带来100个leads,微信带来80个leads。但百度带来的流量最终转化为60个注册用户,微信渠道最终转化了64个注册用户,哪个渠道比较好,不能单纯根据流量来源多少定吧?
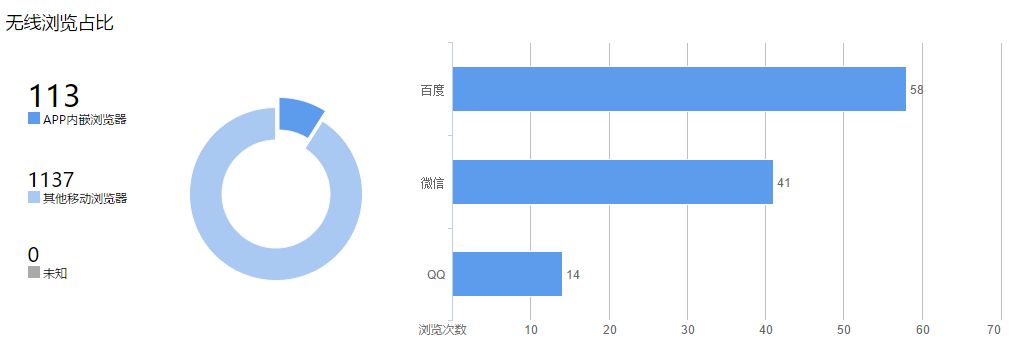
图/数极客用户行为分析工具
大流量、收录高是获得好转化、好排名的基础,是敲门砖。但绝不是决定性的唯一因素。某些情况下,大流量是获得转化的前提,也就我们平常所说的扩大用户池子。在获得流量后需要考虑如何提高产品转化。但某些情况下,流量转化的高低取决于渠道质量的好坏。
3、被动欺骗法
案例一 : 只看数据不考虑其他因素
比如:A入口的留存率是30%,B入口的留存率是50%,大多人都觉得B入口的功能更吸引用户。但你忘记了B入口藏的非常深啊,进到这里的用户都是非常忠实的用户当然留存高啊,这就根本没法说明B比A好。
案例二 : 只关注产品而不关注外界的决定性因素
当年Firefox用户与Mac用户对支付宝重要与否,单从浏览器数据统计看,Firefox访问支付宝的比例太低了。不过因为支付宝不支持Firefox,所以,这个比例不能用作判断的依据。Mac用户也是一样。再说一个,支付宝当年代缴水电煤的项目改版之后,发现缴费用户立刻暴增,产品人员欣喜若狂。后来某同学分析一下,原来那几天是每个月水电煤缴费高峰期,周期性的抽风。其实呢,分析一下我国有关部门发布的数据,你会发现那都是一些说谎的数据。
案例三 : 数字背后对应的内容可能更重要
改版了款wap产品,没做任何推广前提下,发现流量飙升,尤其匿名用户涨了3倍。因为产品本身用户基数低,所以流量翻了两三倍也算正常。当时估计是SNS的口碑传播导致的。但最后还是觉得不对劲,查了一下,发现是搜索引擎在抓页面,因为改版了,所以它们要重新抓一次。空欢喜一场。数字还是那个数字,但背后它到底对应了什么内容,常常被忽略了。在与数据打交道的过程中,我们会因为各种原因,导致分析的结论出现较大的偏颇。
那如何避免被“说谎的数据”欺骗呢?
警惕5大误区,让数据不在说谎
(1)选取的样本容量有误
08年奥运会上,姚明的三分投篮命中率为100%,科比的三分投篮命中率为32%,那么是不是说姚明的三分投篮命中率要比科比高?
显然不能这么说,因为那届奥运会,姚明只投了一个三分球,科比投了53个。
因此,在做数据对比分析时,对于样本的选取,需要制定相同的抽样规则,减少分析结论的偏差性。
抽取样本的方法有:
随机抽样系统抽样整群抽样分层抽样
各种抽样方法的抽样误差一般是:整群抽样≥单纯随机抽样≥系统抽样≥分层抽样。

图/数极客用户行为分析工具
(2)忽略沉默用户
用户迫切需要的需求≠产品的核心需求
产品经理在听到部分用户反馈的时候就做出决策,花费大量的时间开发相应的功能,往往结果,可能这些功能只是极少部分用户的迫切需求,而大部分用户并不在乎。
忽略沉默用户,没有全盘的考虑产品大部分目标用户的核心需求,可能造成人力物力的浪费,更有甚者,会错失商业机会。
(3)混淆关联与因果
某电商网站数据显示,商品评论的数量与商品销售额成正比。即一个商品评论数量越多,那么该商品的销售额也会越高。
假如我们认为评论多是销量高的原因的话,数据分析的结论就会指导我们,需要创造更多的商品评论来带动商品销量。
但如果真的这样操作的话,就会发现很多商品的销量对于评论的敏感度并不一样,甚至很多商品销量很高,但与其评论的多少毫无关系。
这里,我们就需要思考,评论真的是影响销量的必然因素吗?
除了评论之外,影响销量的因素,还有其质量、价格、活动等,如果能完整的认识到这些因素,那我们要拉升商品销量,首先会需要先从其他角度来考虑,而非评论入手。
因此,在分析数据的时候,正确判断数据指标的逻辑关系,是指导我们做出产品决策的前提。
(4)可视化表达方式有误
用来表达数据的图表的长宽,取值的间隔,数据的标准化等都会造成视觉上的误差。
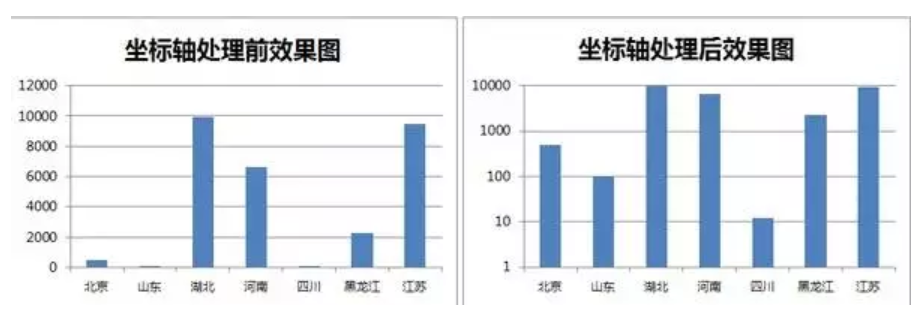
由上图可知,如果数据的取值间隔划分过大(等比数列 1,10,100,1000,10000)而不是标准等差数列(1,2,3,4),则数据之间巨大差异会被缩小。
左图暗示“湖北、河南、江苏总产值排名前三远超其他省市”右图暗示“各省市总产值相差并不太大”
数极客在可视化数据看板里面,采用统一的图表标准,选用最适合企业查看的数据表达方式。不仅拥有可视化图表,而且还有可视化埋点,让数据分析完全自动化,定制化。
图/数极客用户行为分析工具
(5)过度依赖数据
过度依赖数据,一方面,会让我们做很多没有价值的数据分析;另一方面,也会限制产品经理本来应有的灵感和创意。
比如,分析马车的数据,很可能我们得出的结论,是用户需要一匹更快的马车。如果过度依赖数据,局限了我们的思维,就很有可能不会有汽车的诞生。
很多优秀甚至伟大的产品决策,并非通过数据发现的,而是一个产品经理综合智慧的体现。
数据是客观的,但是,解读数据的人是主观的。
只有正确的认识数据,才能正确的利用数据。
强大的功能和严谨的数据分析逻辑已经被越来越多的产品经理,运营人员所推荐。
|
|



 微信扫一扫
微信扫一扫




 发表于 2018-2-17 16:30:43
发表于 2018-2-17 16:30:43
 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏
