设为首页
收藏本站
用户名
Email
自动登录
找回密码
密码
登录
立即注册
只需一步,快速开始
快捷导航
登录
注册
论坛首页
BBS
建站模版
微站设计
虚拟主机
企业邮箱
博客日志
Blog
搜索
搜索
搜索
热搜
长春
优惠
活动
做网站
本版
帖子
用户
本版
帖子
用户
请
登录
后使用快捷导航
没有帐号?
立即注册
道具
勋章
任务
留言板
设置
我的收藏
退出
时时商务社区
»
论坛首页
›
建站资源
›
建站技术
›
产品策略算法——神奇的对数
返回列表
查看:
280
|
回复:
0
产品策略算法——神奇的对数
[复制链接]
qz234
当前离线
积分
7694
2588
主题
2588
帖子
7694
积分
论坛元老
论坛元老, 积分 7694, 距离下一级还需 9992305 积分
论坛元老, 积分 7694, 距离下一级还需 9992305 积分
积分
7694
发消息
电梯直达
楼主
发表于 2018-2-17 16:35:34
|
只看该作者
|
倒序浏览
|
阅读模式
在产品策略公式中,如果加减乘除实在搞不定,那么你可以试着用一下对数。
1、生活中的对数
作为一个数学渣,实在无力从对数的起源开始一番复杂的推导然后再得出结论。直接给出一个判断吧——需要用对数处理才能很好计算的数据,基本上都是符合长尾分布的数据。
长尾分布的特点是,少数的item集中了大量的份额,但是在数值上,尾部的item的数值下降非常缓慢,不会直接下降为零。这么说可能有点苍白,那么举几个例子好了。
人的收入,年收入1万~10万的人是大多数,年收入10万~100万的比较少,年收入大于1000万的更少,但是年收入大于1000万的人却占据了社会财富的大多数份额。
电商中,店铺销量最高的店铺占据了GMV的大多数,商品头部爆款占据了GMV的大多数。
知乎中,头部的大V占据了大多数的关注,高票答案占据了知乎大多数的赞同。
自然界,对于地震的衡量是使用对数的,地震等级每相差2级,能量增加1000倍。
人的感觉上的强度,大约和刺激强度的对数成正比。比如,我们感觉声音大了一倍,不是因为声源功率增加了一倍,而是声源功率增加了一个数量级。
2、一个几乎万能公式
其实在之前的文章中,不止一次出现过对数的使用。比如:
在《
Feed流设计:怎样用策略掌控用户视线
》中,介绍了一个来自Reddit的核心排序算法,在兼顾了Feed流中头部都是热门数据的基础上,能够自动完成数据的更新。
在《【搜索Case分享】五分钟,教你优化知乎搜索》中,最终给出的用户搜索排序算法,既保证了用户之间的关注关系得到了尊重,也保证了用户的搜索相关度得到了尊重,同时也保证了粉丝数和赞同数能起到作用。
这些例子其实都是下面这个几乎万能的公式的变形:
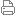
其中a代表根据需求需要调整的参数,M代表业务数据,M之所以要+1,一方面是历史的进程,另一方面也是为了保证
为正值。这个公式是为了平衡长尾分布的业务数据与有界的关键性数据之间的关系。
这个公式之所以说万能,是因为大部分产品数据都可以分为长尾分布的业务数据,或者有界的关键数据。比如搜索就是典型的例子,长尾的业务数据就是销量或者点击量,有界的关键性数据就是文本相关度。
3、策略公式的应用
接下来就是举例子的时刻了。
场景一:假如淘宝店铺,年末要搞一个最佳店铺排行榜
这个时候肯定是要用到GMV(销售额),也需要用到DSR(detail seller rating,就是宝贝描述,服务态度,发货速度这些)。上面我们已经讨论了,淘宝的销量是数量差别是非常大的。大店铺每月销售额10亿的数量级,小的精品店10万销售额也不错。如果单纯用销量去排列,很多精品店无法挖掘,如果单纯用DSR排列,则不考虑GMV,这无法体现大店铺的优势。
这个问题中,DSR是有界性关键指标,GMV为长尾分布的业务数据。那么排序公式可以是:
假如a取1:
一个GMV为1亿,DSR为4分内的店铺A分数为11
一个GMV为1000万,DSR为3分的店铺B分数为10
另一个GMV为100万,DSR为4.5分的店铺C分数为10.5
A>C>B,比较起来就比较公平,一个店铺的命运当然要考虑自己的努力(DSR),但是也好考虑历史的进程(GMV)。
场景二:知乎要搞一个知乎最佳贡献者排行
这个时候既要考虑这一年收获了多少赞,也需要考虑这个人的答案质量,假如粗暴地认为答案质量度为(阅读+5*点赞+15*收藏)/曝光次数,如果只考虑质量度,笔耕不辍的人怎么办?如果只考虑收货赞的数量,那么一些长期抖机灵没营养的人可能会占便宜。
这个问题中,质量度是有界性关键指标,点赞数为长尾分布的业务数据。那么排序公式可以是:
假如a取1:
一个用户A答案质量度为5,赞同数为1万,则得分为9
一个用户B答案质量度为3.5,赞同数为10万,则得分为8.5
用户A排名大于B。
场景三:如何帮三毛找对象?
荷西问三毛:你想嫁个什么样的人?
三毛说:看的顺眼,千万富翁也嫁。看的不顺眼,亿万富翁也嫁。
荷西就说:那说来说去你还是想嫁个有钱的。
三毛看了荷西一眼说:也有例外的时候。
“那你要是嫁给我呢?”荷西问道,
三毛叹了口气说:要是你的话那只要够吃饭的钱就够了。
“那你吃的多吗?”荷西问道。
“不多不多,以后还可以少吃一点。”三毛小心的说道。
在这个例子中主观评分的是否顺眼为关键性指标(假设为1~5),财富值为重要的业务指标。那么排序公式为:
因为三毛非常看重是否match(顺眼),所以a我们假设为2,那么:
千万富翁A,顺眼指数为4,则得分15;
亿万富翁B,顺眼指数为2,则得分12;
荷西没钱,顺眼指数为5,则得分为10。
这个时候我们发现这个公式没有解决问题,荷西不是最高的。三毛会选择千万富翁。
hmmm,这就是为什么我说这个公式是一个几乎万能的公式,而不是万能的公式。因为总有些异常的case需要进一步处理。
如果算法改为:
if(name=“荷西”)
{
score=100;
}
else
{
;
}
这个问题就迎刃而解了。
4、总结
这确实是一个几乎万能的公式,但是M值怎么选取,X值怎么选取,参数怎么制定,就需要产品经理对业务有自己的思考了。业务理解力是前提,公式的灵活运用,都是在业务理解力的前提下才能发挥作用。
理解公式是一个层次,灵活运用公式是一个层次,而在灵活运用公式的同时,再加上对业务的思考,则又是另一个层次了。
本文在使用的案例的都是比较理想案例,在真实案例中,数据往往不能直接比较,而是设置不同的参数,那么有什么常见的阐述设置情形呢?又有什么常见的参数设置方法呢?
分享到:
QQ好友和群
QQ空间
腾讯微博
腾讯朋友
收藏
0
回复
使用道具
举报
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
用户反馈
客户端



 微信扫一扫
微信扫一扫




 发表于 2018-2-17 16:35:34
发表于 2018-2-17 16:35:34







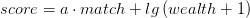

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏
